
Chess computers have been good enough to beat me my whole life. It took until 1997 for them to beat a reigning World Champion, when Deep Blue beat Kasparov. They can now comfortably beat all the best players in the world. But development of Go computers has been far slower, it was only this year that AlphaGo defeated Lee Sodol, the 9 dan professional. What is the difference?
The most common reason given for why Go is harder, is that it is more complicated. In chess, there is a choice of 20 first moves, in Go the choice is 361. So in Go, the permutations and, as a result, possible games are far higher than in chess. Since computers play these games by simulating permutations, it makes intuitive sense that this is easier in chess than Go.
This argument is logical but highly misleading. The problem is that BOTH games are insanely complex and unsolvable by brute force. Imagine I am trying to move a pair of large rocks. One weighs 100 tonnes. The other weighs 10,000 tonnes. Is it sensible to say that the second is 100 times harder to move? Or simply that both are unmovable. Degrees of impossibility is not a very useful concept.
There is a more important difference between the two games. In chess we can build a simple model that acts as an excellent first approximation to evaluate who is winning. Just count the material and use a simple scoring of queen= 9 pawns, rook = 5 pawns etc. to come up with a single total for both sides. The one with the higher number is winning. This is how beginners think of the game, the aim is to grab material. Thus, it is easy to code a simple model to get the computer started. Once this first order approximation is worked out then second order models can be added such as pawn structure, space advantage or use of open files. In Go there is no such simple evaluation metric and how they managed to programme a computer to win is a fascinating topic and likely a separate post on AI.
A good first order approximation often gets you a decent way to a solution. If you don’t have this, you may have trouble finding a solution that doesn’t take an infinite amount of time to solve, as the early versions of Go computers found.
This has an interesting link to the way I approach financial markets and economics. I think it is most important to spend time thinking about appropriate first order approximations to help with the general understanding of what is really going on. But the influences around us often obscure this, for example from news or complex analysis.
Reminiscences of a Stock operator
I first read this book when I was 17 but it took me many years of trading and painful experiences to realise that the character who had the most to teach me was Partridge. He is the older, experienced trader who whenever presented with a stock tip by an excited young trader would always reply
“Well, this is a bull market, you know!” as though he were giving you a priceless talisman wrapped inside a million-dollar accident-insurance policy. And of course, I did not get his meaning.
Useful trading models
In economics and finance, it is the development and understanding of models of a first approximation that are the most useful and the most important. This is primarily the method I am using for models of asset market pricing described in other posts. Far too much effort and time is spent on far more “complex” analysis and models, which often focus on second or third order drivers by assuming away the first order ones. The “news” constantly blaring out on cable TV is at best a focus on factors causing minute differences in asset prices. At worst, it is just distracting white noise. Precise directions for the last 100m of your trip are a not much use if you are not sure which town you are going to. It is far better to be approximately right than to be precisely wrong.
Trade Ideas
A common type of trade idea proposed to me will be in this form:
- There is a recent development or upcoming event which matters for the Australian dollar (substitute in any other market) e.g. a piece of economic data
- We should buy/sell it
What is rarely done however, is considering how important this driver is in context. Commonly the idea is logical but essentially rests on the idea that the current market price is already correctly priced. This approach fits well with many people’s education in which assumptions of efficient markets are often embedded without them realising. The reason that these trade ideas often fail is that the new information will only dominate the market movements if and only if the more important drivers of the currency are correctly priced. Instead of assuming the market is fairly priced, I would prefer to question whether this first order approximation is appropriate before moving on.
Australian Dollar Example
To use an Australian dollar example, the value of the currency doubled between 2001 and 2008

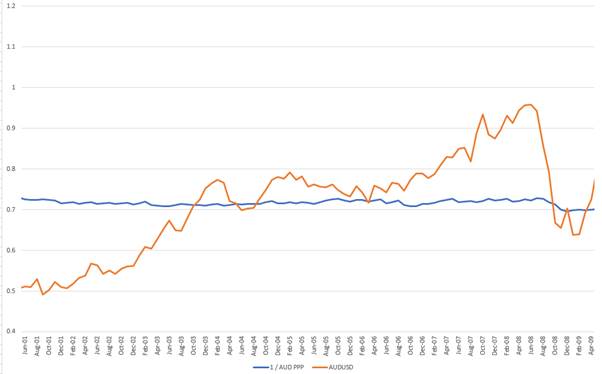
It did not rise like this because of a succession of incremental pieces of random news which happened to cumulate in a massive movement. It happened because the currency was by first order approximation far too cheap. A useful first order approximation model for currencies is Purchasing Power Parity (indices are freely available and calculated by the OECD). The chart below shows that the PPP of the AUD was very steady at around 0.70 cents. In 2001 it was very cheap, and when it approached parity it was very expensive. Capturing these kinds of move is where I spend my time and historically where I have made my biggest profits.
Conclusion
I have learned to focus on the bigger picture and look for large market movements. In my experience, these are most likely to happen when the market price is a long way from a good first approximation model. I therefore put time into building these first approximation models across asset classes as I have briefly described so far in fixed income, and will follow up with ones on currencies and equities. Just as in chess, a good understanding of a first approximation model can get you a long way. Focusing on very new information or complex models which are actually third order features, while neglecting the first order drivers, only leads to confusion and major mistakes.

First order approximation seems to mean something quite different in economics and markets than in physics (or even chess). For example, one of key visual observations about AUD/USD and the PPP model is that the currency spends a lot of time away from PPP. Since 1980, the gap between the two has been greater than 10% over half of the time (based on monthly observations) and since 1998 it has spent almost 70% of the time farther apart than 10%.
In another context, there is a standard mistake in policy setting to change a variable and expect the direct effects to capture most of the impact. In that case, the response to the policy is often a much bigger factor.
I hope you had a chance to watch and enjoy some of the games from the Future of Go Summit this past week. Unfortunately, I only have had time to watch part of the first Ke Jie match. However, that match does have a very nice example of how local and global considerations can mix in subtle ways. If I recall correctly, it was white 66 whose purpose got revealed to the human commentators around move 80 when it influenced play on the other side of the board.
Also, a technical quibble: because of symmetry, there are only 55 distinct opening moves in Go.
LikeLike
Thanks. This has sparked a lively debate about the meaning of “1st order approximation”. It seems a good example of a phrase which is a jargon phrase in a number of disciplines with different formal and informal definitions. I think i may write a separate post about this topic.
On the quibble – I agree that there while there are 361 opening moves (19×19) they can be seen as only 55 distinct moves, due to symmetry. This must be a very easy thing to programme the computer to do as a first step to reduce the number of permutations it needs to separately calculate. However, I have read that there are a googol more possible games of Go than chess. Even if this estimate can be brought down by symmetry, a googol is a very large number.
LikeLike
This point about “1st order approximation” relates to the nice discussion of linear extrapolation in Jordan Ellenberg’s book.
In any case, symmetry is usually broken pretty quickly, so that method of complexity reduction isn’t very powerful.
Putting aside all possible games, I’ve heard the comparison that, at a typical time during the game, there are:
– 3-5 chess moves worth considering
– 20-50 go moves worth considering.
This number is so large because, somewhat comforting for a beginner, if one point is a good move, points near-by are often also good moves. However, frustrating for a beginner, even choosing between directly adjacent points can make a big difference later in the game.
LikeLike