Here is a metaphor to explain how to approach a situation when there are conflicting potential drivers of an asset.
You are sitting on a small yacht, drifting in the sea. You want to know in which direction you will drift: onto those scary rocks or safely away from them. There are two potential factors which could be very important – the wind and the tide. The wind is the one you will be most aware of; but the tide could perhaps be very important even though it is less clear what it is doing.
If you ask for help you may find advice split into 2 camps. Those who believe that the wind is always the critical factor and those who believe that the tide is always the critical factor. This ideological split is not very helpful because there is no consistent answer to this problem. Sometimes the wind will matter more, sometimes the tide will matter more. You have to use your knowledge and judgement to decide how to incorporate those factors.
As for asset markets, this is a useful metaphor for many macro markets from fixed income, to equities to foreign exchange. A clear and important example of this today is how to position ourselves in the USD.
FX Model
Tide – Value (proxy is the real effective exchange rate)
Wind – Relative monetary policy.
Monetary Policy (Wind)
Most FX strategy I have read over the past few months has been bullish the USD. The most common argument relates to divergence of monetary policy. The Fed is raising rates when few other countries are, and with Trump these expectations became even stronger.
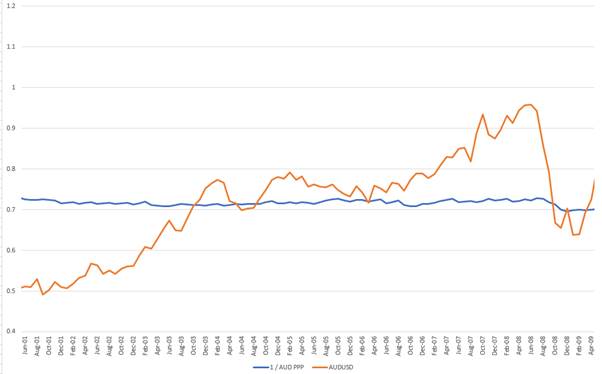
The relationship between the movement of a currency and the relative interest rates in those countries is a good one. If we look at the last decade of the Euro vs the US dollar then we see what a great first approximation it is.
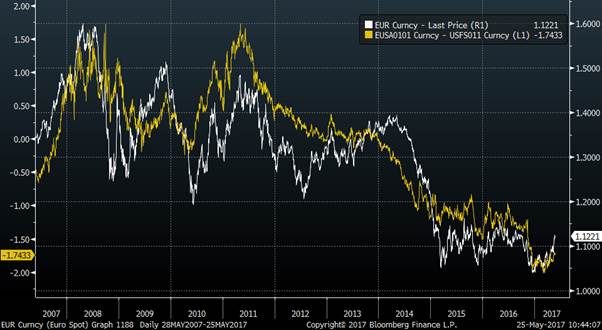
But in financial markets, it is often a mistake to assume that something you have found that works well for a period is always reliable. It is not possible to treat macroeconomics or investing as having “Laws” in this sense.
If we look at the prior decade for the Euro, then the monetary policy model is terrible.
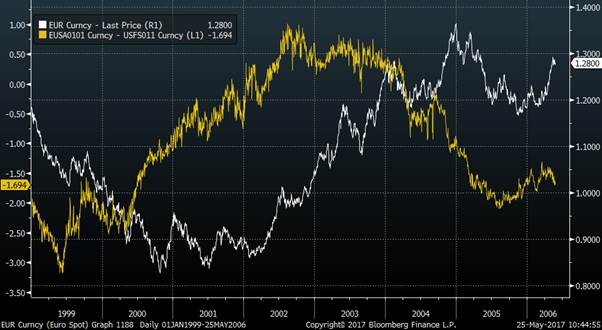
Value (Tide)
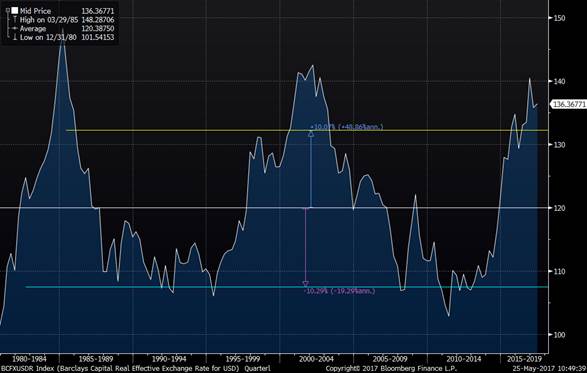
The other first approximation model I want to look is value. For this post, I will take the real effective exchange rate (REER) as a simple proxy.

It is clear from this chart that assuming a mean-reverting tendency in the REER would not have been at all useful in the past 3 years. The USD has been above its average value and heading higher strongly.
Maybe value only matters at extremes? Taking a longer view, adding bands of +/- 10% gives us a sense of how far the USD can move before a value constraint starts to be meaningful.
If you take the model for the yacht as the same conditions last time you went sailing, when there was not much tide and the wind blew you safely away from the rocks, this is not sensible. It would be particularly dangerous if there is a rip tide and you are ignoring it by assuming that a light breeze will determine your path.
Why is everyone talking bullishly about the USD?
- Recently value has been a terrible model.
The US dollar is expensive and going higher - Rates differential has been a great model
- Simple extrapolation means that people believe rates will continue to be the best model in the future
Signs this may be happening now
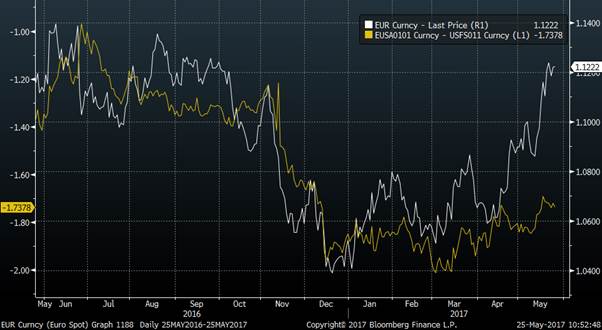
The recent strengthening of the euro is often “explained” with reference to a potential change in QE from the ECB. But rates have not moved. So perhaps we are seeing the influence of a force we have not had to pay attention to recently. Value.
Conclusion
Macro investing is hard. The world is complex and confusing. Over the years I have noticed many people fall into one of two traps
- Become fixed in a single view of how the world works and happily ignore or rationalise away contrary information
- Form a fluid view of the world which adapts to a model which can make the most sense of their recent experience.
The time we can make the most money from markets is when they are the most wrong. This can happen people are using the wrong model.