I played in a two-day golf tournament recently and had a conversation about whether golf handicaps were fair, even for completely honest golfers. As I thought more about it I realised that they are not, but not always in the ways I had imagined. I was aware that both high and low handicappers often thought the system was biased against them. I had not realised that depending on the circumstances they were both right.
What is the handicap for?
According to the USGA “the purpose of the USGA Handicap System is to make the game of golf more enjoyable by enabling players of differing abilities to compete on an equitable basis.”
http://www.usga.org/Handicapping/handicap-manual.html#!rule-14367
But it does not simply create a handicap by taking an average of your scores. It “disregards high scores that bear little relation to the player’s potential ability”. The method mixes up the ideas of “equitable” with “potential” which has profound implications for which golfer should expect to win.
Note I will use the USGA system in this post as it is the system I understand the best. It is worth noting how many different systems are currently used across the world. These other systems will have some impact on the “fairness” but the key points are true for all of them.
How is your handicap calculated? (slightly simplified!)
- Take your score on a full round of golf and adjust it slightly by eliminating any very bad holes. For example, an 18 handicapper records any hole which is more than a 7 as a 7.
- Enter your last 20 adjusted scores and compare them to par e.g. if you have a score of 82 on a par 72 course this is 10 over.
- Take an average of your best 10 scores compared to par. Ignore the worst 10.
- That is your handicap
The same mathematical process has been performed on both players’ data to adjust their scores. Does this mean that the result is fair?
The problem is that the way that golfers of different abilities vary is not just in their average score. They also have different volatilities. A low handicapper has a far more consistent game, which translates from consistency on each shot to each hole score to each total score per round. This difference in volatility of the players has a big impact on who you should expect to win.
Let’s take a simplified case to illustrate the issue. Let the scratch (zero handicap) golfer have zero volatility i.e. they shoot level par gross and net every time. Let the 18-handicapper have a more realistic (and obviously higher) volatility of score.
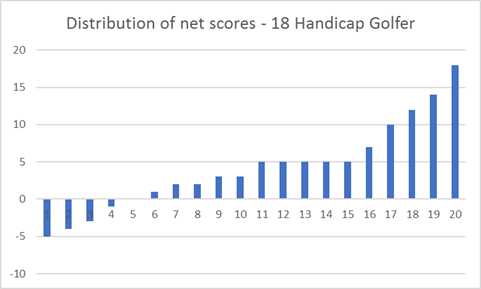
Head to Head – low handicapper wins
If we put these two golfers head to head then it is pretty clear that the low handicapper is very likely to win. The low handicappers “potential” is the same as his average performance. For the high handicapper he has the “potential” to win the match but since his average score is far higher he is pretty unlikely to do so.
High handicapper A wins only 4 times out of 20 while low handicapper B wins 15 times out of 20.
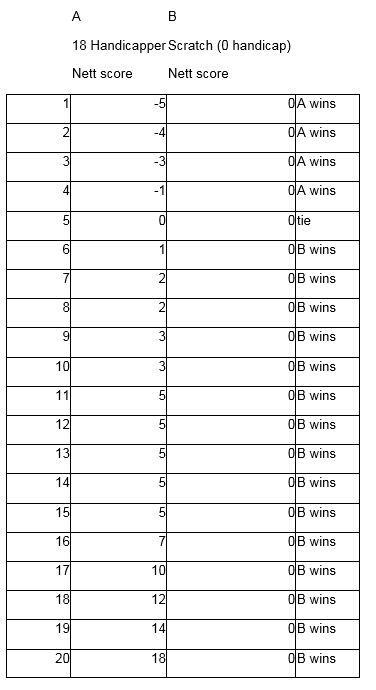
This is often how a high handicapper perceives golf handicaps. They know they are unfair. They get regularly beaten by low handicappers and have (hopefully) learned not to bet with them on the golf course. It is worth noting though that the lower handicapper will still often moan about how unfair it is to give strokes on some particular hole such as a par 3.
What if we make a different handicap system and do not only include the golfer’s “potential” but all the data on how they actually perform. The 18-handicapper actually averages 22 over par and so if we use that as the handicap instead we get this table of results in which each player wins 10 times.
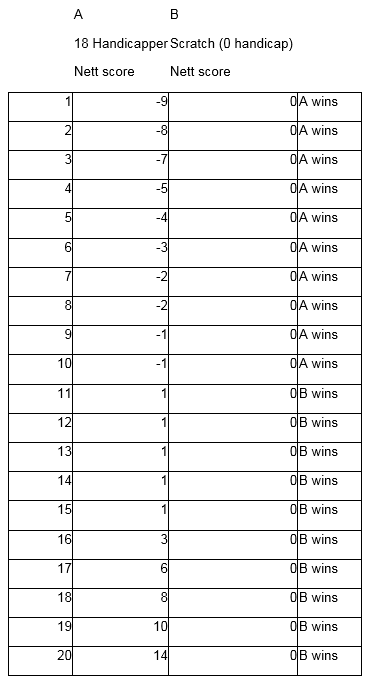
So is this system fairer? Well not necessarily.
Tournament – high handicapper wins
We just saw that the low handicapper has an advantage in head to head competition. But what if there are lots of players in a tournament. Let’s have 40 golfers, 20 scratch golfers who shoot level and 20 18 handicappers with the range of scores.
If we simply rank all the scores then the top 4 in the tournament will be high handicappers having an unusually great day. But the bottom 15 golfers are also high handicappers having a more typical or even poor day.
The low handicapper has virtually no chance of winning a tournament as the top spots will be taken by a high volatility golfer having a good day. This leads to justifiable frustration from the low handicappers and sometimes the incorrect assumption that the high handicappers must be sandbaggers.
Summary
- In head-to-head competition, the low handicapper has a large advantage
- In a tournament, a high handicapper is more likely to win
How to combat the problem?
I see problem 2 combatted very frequently. It is common for only a fraction of the handicap to be actually used, such as 2/3 or ¾. I do not have the data to know whether this makes it equally likely for a low and high handicapper to win. But I will be extremely confident that there will be a host of high handicappers with very poor net scores at the end of that event. So even making it “fair” in terms of the overall winner will not result in all participants feeling that way.
I have never seen problem 1 addressed. In practice if anything I tend to see the lower handicapper try to argue for a reduction in strokes given!
A theoretical solution
A theoretical solution would be to recognise that a single number cannot cover both of
- Difference in average score
- Difference in volatility of score
A revised system could involve a measure of both.
I do not think this is a sensible idea. It would be complex and given the poor quality of the underlying data (self-reported ad hoc scoring) it would be hard to rely on it.
My solution
Head-to-head handicap gold tends to be social and there are more fun ways to decide a handicap. For a regular partner, the winner has to give an additional stroke the next time you play. I doubt you will convince them to give you more strokes any other way.
Handicap golf tournaments perhaps should not be taken too seriously. The system does a decent job and will make the contest close enough and the result uncertain enough to be fun. With the common correction in tournaments everyone has a chance (unless there are real sandbaggers of course) but high handicappers have to accept they have a good chance of a terrible score.
But maybe that is just because I have been playing this tournament for 15 years without winning anything….
Next steps for golf
The global handicap system is being revised.
http://www.randa.org/News/2017/04/World-Handicap-System-to-be-developed-for-golf
I will be interested to see how they deal with the issues.